ChatGPT발 AI혁명은 지금 어디까지 와 있는 것일까요?
ChatGPT가 인간의 수행 능력을 어디까지 대체하고 있고, 어떤 영역에서 앞서고 있는지 금일 알아보도록 하겠습니다.

AI vs. 인간
ChatGPT 폭발적인 사용증가 와 함께 AI는 특히 독해력, 음성 인식 및 이미지 식별과 같은 전통적인 인간의 수행 능력을 앞서가고 있습니다.
실제로 아래 차트를 보면 AI가 꽤 많은 영역에서 인간의 성능을 능가했으며 다른 곳에서는 인간을 능가할 것으로 전망할 수 있습니다.
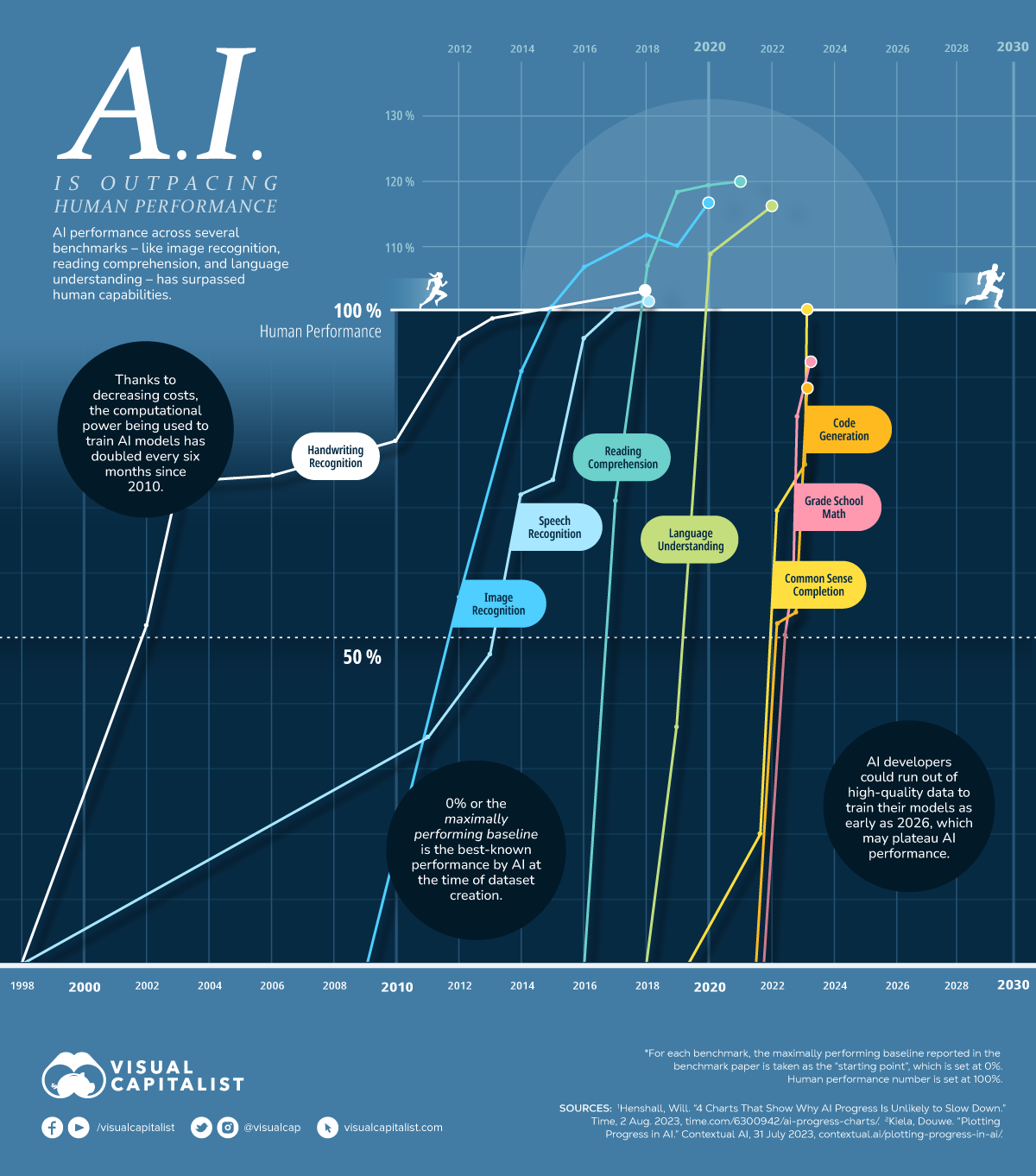
연구 방법 (벤치마크 적용 가이드라인)
상황별 AI 의 데이터를 사용하여 AI 모델이 얼마나 빨리 벤치마크를 능가하기 시작했는지, 그리고 AI가 아직 인간 수준의 기술에 도달했는지 여부를 시각화하여 보여줍니다.
각 DB는 필기 인식, 언어 이해 또는 독해와 같은 특정 기술을 중심으로 고안되었으며, 각 백분율 점수는 다음 벤치마크를 기준으로 산정됩니다.
- 0% 또는 “최대 성능 기준” : 이는 데이터 생성 당시 AI가 가장 잘 알려진 성능과 동일합니다.
- 100% : 데이터 세트에서 인간의 수행 능력과 동일합니다.
이 두 지점 사이에 척도를 생성하면 각 데이터세트의 AI 모델 진행 상황을 추적할 수 있습니다. 선의 각 점은 최상의 결과를 나타내며 선이 위쪽으로 향할수록 AI 모델은 인간 성능과 일치하는 수준에 점점 더 가까워집니다.
다음의 표는 AI가 8가지 기술 측면에서, 우리 인간의 수행능력과 일치되기 시작한 시기를 보여줍니다.
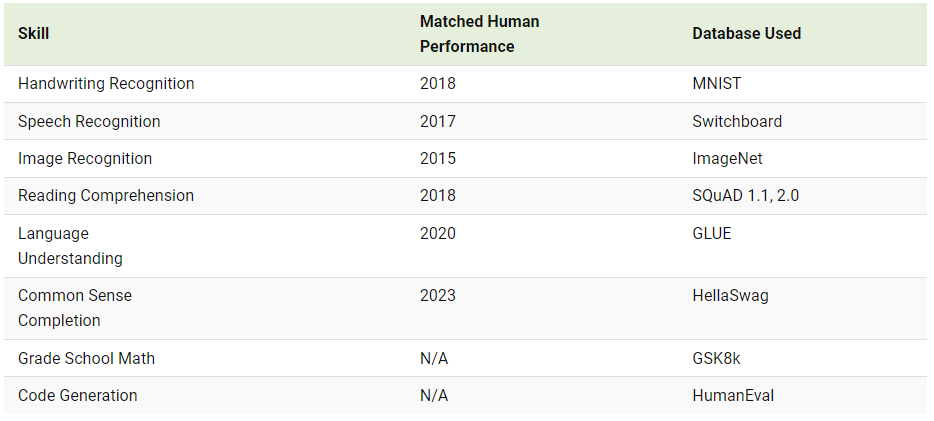
해당 차트는 2010년 이후 얼마나 많은 진전이 이루어졌는가를 보여줍니다. 참고로, SQuAD, GLUE, HellaSwag 등 이러한 데이터베이스 중 대부분은 2015년 이전에는 존재하지 않았습니다.
벤치마크가 더 이상 사용되지 않게 되면서 일부 최신 데이터베이스는 새롭고 관련 있는 데이터 포인트로 지속적으로 업데이트하고 있다고 합니다. 이는 AI 모델이 기술적으로는 잘 진행되고 있음에도 불구하고, 일부 영역(초등학교 수학 및 코드 생성)에서 아직 인간의 성능과 일치하지 않는 이유입니다
AI가 인간을 능가할 수 있는 이유
지난 몇 년 동안 AI의 능력이 이렇게 빠르게 성장할 수 있었던 이유는 무엇입니까?
컴퓨팅 성능, 데이터 가용성 및 향상된 알고리즘 덕분에 AI 모델은 10년 전보다 더 빠르고, 학습할 수 있는 데이터 세트가 더 광대하며, 효율성에 최적화되어 있습니다. 좀 더 구체적으로 풀어볼까요.
- 계산 속도와 데이터 처리 능력: AI 시스템은 매우 빠른 계산 속도와 대용량 데이터를 신속하게 처리할 수 있는 능력을 갖추고 있습니다. 이를 통해 AI는 복잡한 문제를 빠르게 분석하고 판단할 수 있습니다.
- 기계 학습과 패턴 인식: AI는 기계 학습 알고리즘을 사용하여 데이터에서 패턴을 인식하고, 이를 기반으로 예측과 결정을 내릴 수 있습니다. 이러한 학습 과정은 반복되며, AI 시스템은 점차적으로 경험과 지식을 쌓아나갑니다.
- 대규모 데이터 활용: AI 시스템은 대규모의 다양한 데이터를 활용하여 학습하고 문제를 해결합니다. 인간이 처리하기 어려운 방대한 양의 데이터에서 의미 있는 정보와 통찰력을 도출하는데 우수한 성능을 보입니다.
- 지속적인 개선과 업그레이드: AI 시스템은 지속적으로 발전하며 개선됩니다. 새로운 알고리즘, 모델 및 기술의 도입으로 성능이 향상되며, 그로 인해 인간의 한계를 넘어서기도 합니다.
이것이 AI 언어 모델이 표준화된 테스트에서 인간의 성능과 일치하거나 능가하는 것에 대해 일상적으로 이야기하는 이유입니다. 앞으로 몇 년 안에 더 많은 컴퓨팅 및 알고리즘 향상이 예상되므로 이러한 급속한 발전은 계속될 것입니다.
그러나 AI 발전의 다음 잠재적 병목 현상은 AI 자체가 아니라 모델을 훈련할 데이터가 부족하기 때문일 수 있습니다.
AI의 한계와 제약사항
그럼에도 불구하고 AI의 한계와 제약 사항이 있음을 우리는 고찰해 보아야 할 것입니다.
- 데이터 의존성: AI는 대량의 데이터를 기반으로 학습하고 판단합니다. 따라서 충분한 양과 질의 데이터가 없거나 표현력이 부족한 데이터로 학습된 경우, 정확성과 일반화 능력에 제약이 생길 수 있습니다.
- 사전 정의된 범위: AI 시스템은 주어진 범위 내에서 작동하며, 그 범위를 넘어선 문제에 대해서는 처리하기 어렵습니다. 새로운 상황이나 예기치 않은 입력에 대해서는 예상치 못한 동작을 할 수 있습니다.
- 윤리적 고려사항: AI 시스템은 학습 데이터에 내재된 편견이나 인간의 행동 모델을 반영할 수 있습니다. 이로 인해 차별이나 불공정한 결정을 내릴 수도 있으며, 이를 해결하기 위해 윤리적인 가이드라인과 규제가 필요합니다.
- 추론 및 설명 가능성 부족: 일부 AI 모델은 결과를 도출하는 과정을 설명하기 어렵거나 추론 과정을 완전히 이해하기 어렵습니다. 이는 신뢰성과 투명성 측면에서 문제가 될 수 있으며, 의사 결정에 영향을 미칩니다.
- 상호작용 및 감정적 연결 부재: 현재의 AI 시스템은 인간처럼 상호작용하거나 감정적으로 연결되지 못합니다. 이러한 면에서 사회적 관계 형성, 감정 지능, 심리적 지원 등 인간의 역할을 대체하기 어렵습니다.
AI 기술의 발전은 위 제약 사항들을 극복하고자 지속적인 연구와 개선 작업이 진행되고 있지만, 현재까지도 인간과 AI 간의 협력과 상호보완 관계가 필요함을 알 수 있습니다.
ChatGPT 시험 테스트 결과
추가적으로 현재 ChatGPT의 수행 능력을 비교해볼 수 있는 자료가 있어 함께 공유코자 합니다.
ChatGPT-4가 런칭되면서, 우리 인간들이 주요 시험에 대한 ChatGPT의 수행능력을 평가한 자료를 공유하였습니다.
2023년 3월 27일에 발표된 기술 보고서에 따르면, OpenAI는 GPT-4로 알려진 최신 모델에 대한 포괄적인 개요를 제공했습니다. 이 보고서에는 아래의 그래픽에 시각화된 일련의 시험 결과가 포함되어 있습니다.
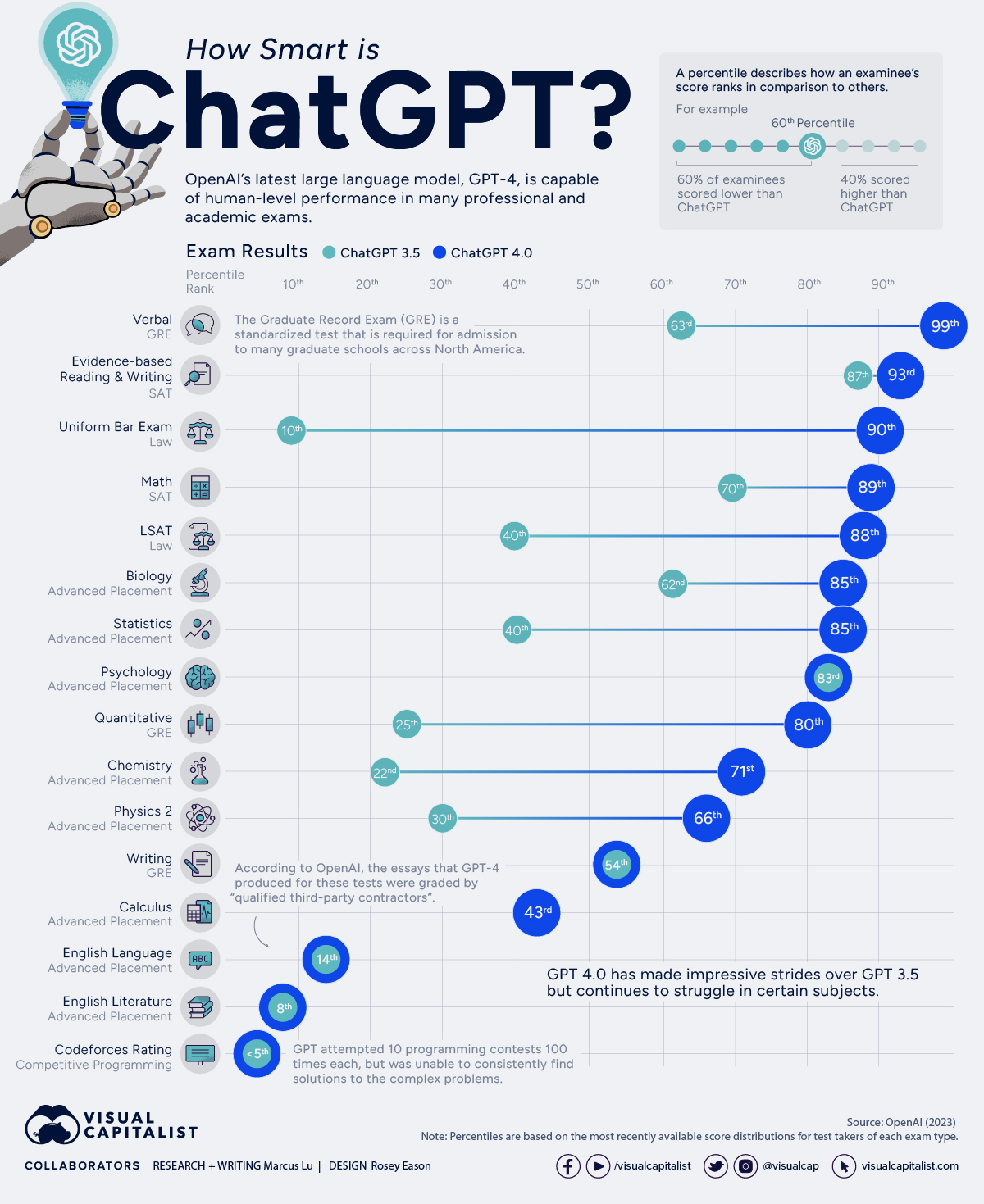
ChatGPT-4 vs. ChatGPT-3.5
ChatGPT의 기능을 벤치마킹하기 위해 OpenAI는 다양한 전문 및 학술 시험의 시뮬레이션 테스트를 실행했습니다. 여기에는 SAT, 변호사 시험, 다양한 AP(Advanced Placement) 시험이 포함됩니다.
해당성적은 각 시험 유형의 응시자에게 가장 최근에 제공되는 점수 분포를 기반으로 한 백분위수 로 측정되었습니다 .
백분위수 점수는 다른 사람의 성과와 비교하여 자신의 성과 순위를 매기는 방법입니다. 예를 들어, 시험에서 60번째 백분위수에 속했다면 이는 응시자의 60%보다 높은 점수를 받았다는 의미입니다.
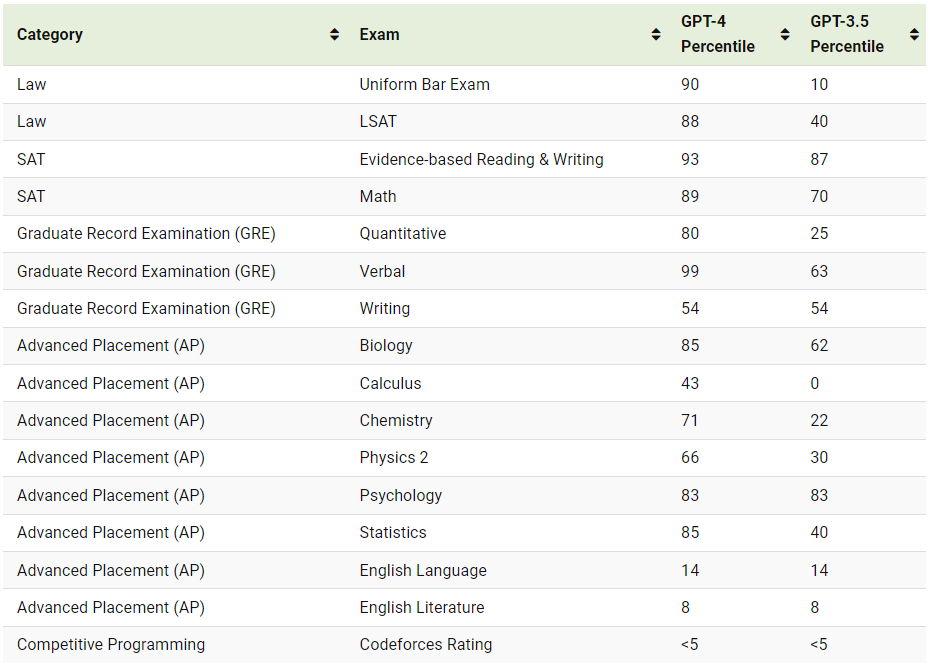
보시다시피, GPT-4(2023년 3월 출시)는 대부분의 시험에서 GPT-3.5(2022년 3월 출시)보다 훨씬 뛰어난 성능을 발휘합니다. 그러나 AP 영어 와 경쟁 프로그래밍 에서는 향상되지 않았습니다.
AP 영어(및 서면 답변이 필요한 기타 시험)와 관련하여 ChatGPT는 "해당 에세이를 채점하는 관련 업무 경험이 있는 자격을 갖춘 제3자 계약자 1~2명"에 의해 등급이 매겨졌습니다. ChatGPT는 확실히 적절한 에세이를 작성할 수 있지만 시험의 프롬프트를 이해하는 데 어려움을 겪었을 수 있습니다.
경쟁력 있는 프로그래밍을 위해 GPT는 10개의 Codeforces 콘테스트를 각각 100회 시도했습니다. Codeforces는 참가자들이 복잡한 문제를 해결해야 하는 경쟁적인 프로그래밍 콘테스트를 개최합니다. GPT-4의 평균 Codeforces 등급은 392(5번째 백분위수 미만)인 반면 단일 콘테스트의 최고 등급은 약 1,300이었습니다.
ChatGPT-4의 주요 변경사항
GPT-4가 GPT-3.5에 비해 사용자 경험을 개선한 몇 가지 영역은 다음과 같습니다.
1) 인터넷 액세스 및 플러그인
GPT-3.5의 제한 요소는 인터넷에 접속할 수 없고 2021년 6월까지의 데이터에 대해서만 교육을 받았다는 것입니다.
GPT-4를 사용하면 사용자 는 ChatGPT가 인터넷에 액세스하고 최신 응답을 제공하며 광범위한 작업을 완료할 수 있도록 지원하는 다양한 플러그인 에 액세스할 수 있습니다. 여기에는 ChatGPT가 전체 휴가를 예약할 수 있도록 해주는 Expedia와 같은 서비스의 제3자 플러그인이 포함됩니다.
2) 이미지 입력
GPT-3.5는 텍스트 입력만 허용했지만 GPT-4는 이미지 분석도 가능합니다. 사용자는 ChatGPT에 사진 설명, 차트 분석, 밈 설명 등을 요청할 수 있습니다.
3) 더 많은 텍스트
마지막으로 GPT-4는 훨씬 더 많은 양의 텍스트를 처리하고 대화를 더 오랫동안 유지할 수 있습니다. 참고로 GPT-3.5의 최대 요청 값은 4,096개 토큰으로, 이는 대략 3,000단어에 해당합니다. GPT-4에는 두 가지 변형이 있습니다. 하나는 8,192개 토큰(6,000단어)이고 다른 하나는 32,768개 토큰(24,000단어)입니다.
[생성AI] 나만 알고 싶은 이미지 만들어주는 5개 AI사이트 추천 (23년)
요즘 ChatGPT에 흠뻑 빠져서 블로그에 글을 정리할 심리적 여유도 없었던 것 같습니다. 생성AI들이 몇년전부터 상용화되고 있었지만, 기술의 발전은 제가 생각했던 것 이상으로 어느새 우리의 삶
eternalhumble.tistory.com
'글로벌정세 > 경제' 카테고리의 다른 글
| 미국 기준 금리 인상의 역사 (1988~2023) (4) | 2023.06.14 |
|---|---|
| [소비자신뢰지수] 2023년 전세계 소비자신뢰지수 하락추세 지속 (8) | 2023.02.20 |
| [빅테크기업] 빅테크 기업의 정리해고, 인력감원 현황 (23.1월) (0) | 2023.01.08 |
| [글로벌 빅테크 기업] IPO vs. 현재 기업가치 (Apple, Amazon, Microsoft, Alphabet, Tesla) (8) | 2022.12.30 |
| [미국 4대 빅테크 기업] 애플/알파벳/아마존/마이크로소프트 실적 정리 (2022.2분기) (13) | 2022.10.13 |

댓글